Summary of the project
Crop farming in Minecraft can be quite a time consuming process: to get any significant benefit in the game, we have to first find suitable spots for the seeds to grow, and then physically go to each of those locations to plant them. The locations we find, as a human user, may not even be optimal planting positions, especially if the mechanics of minecraft farming aren't known. So to make the process quicker and easier we have made a tool that allows an AI to do the farming process for you and save more time for you to do whatever else you want to do in the game. The final aim of this project is to have an agent that, given a map, and some farmable objects defined by the user (wheat, pumpkin seeds etc), will plant the objects for the user in an optimal position.
For this MVP version of the project, we are essentially creating a genetic algorithm AI to find the best points of farmland on a map to plant wheat crops in. Results from farming in minecraft can vary greatly based on a number of criteria, which our agent will use to evaluate positions on the map, and eventually select the optimum locations for farming. The criteria include:
- Terrain: which block you place seeds on directly influences crop yield
- Proximity to water: the closer to a river/water, the faster crops grow
- Light: even if artificial, more light generally means a higher crop yield
- Material Additions: Materials like Bone Meal can help make crop yield faster
Our agent is tasked with applying these criteria to evaluate locations on the map and efficiently select the best locations for farming
Approach
We will be using a Genetic Algorithm to solve this problem, which essentially involves mapping the problem to a graph search problem and following a procedure of breeding successful states to allow our seeds to converge onto an optimal location.
Setup
To set the agent up with what it needs, we do the following:
- First, for this MVP version of our project, we generate a very simple world, which is essentally a square
grid containing:
- A water square at (0,0)
- Dirt around the water from (-10,10) in the (x,z) directions
- The agent is given a range of squares to plant in, which for our purposes, are any of the squares in (-10,10): the agent is successful if he puts a majority of the seeds in the hydrated square region at the end of the algorithm
Now our agent is given 10 seeds, and can follow one of 2 methods:
-
We wrote a function that plants seeds randomly, to measure a baseline performance. In a world of (-10,10) dirt blocks,discluding the water block at the center, our agent can plant on an area of:
Height: -10 to 10 => 21 blocks
Width: -10 to 10 => 21 blocks
Water block at (0,0) => 1 block to remove from the area21² - 1 = 440 blocks
This is the total range that we can plant on
Of these however, only a subset of blocks between (-4,4) are plantable. This leaves an optimal area of
Height: -4 to 4 => 9 blocks
Width: -4 to 4 => 9 blocks
Water block at (0,0) => 1 block to remove from the area9² - 1 = 80 blocks
440 ÷ 80
≅ 18%So theoretically, 18% is the random agent success rate for this map
- Our agent will compare this 18% success rate to its genetic algorithm, evaluated below
The Algorithm
Our algorithm essentially simulates placing the seeds on the map, and evaluates this potential placement using our scoring function. It will do this until convergence. The steps to our genetic algorithm are as follows:
- We initialise 10 random seed locations [this could be any integer value less than the map area], stored as (x,z) tuples [Y is implicitly the same as we do no digging]
- For 10 rounds, we:
- score the current seed locations using our scoring function, which essentially measures distance to the nearest water block
- take 5 "elite" seeds: that is, the best scoring seeds from the group. These 5 seeds automatically pass to the next round of seed locations
- using the same 5 best seeds, generate 5 new children seeds by using their attributes. In this simple version of our algorithm, we essentially randomly take the x and z coordinate from either of the parents. This is a simple approach, but is quite effective is generating good results.
- The 5 best seed locations are taken along with the new 5 children, ready for the next round. The worst 5 "die"
- Randomly mutate one of the seed locations by adding a mutation vector, which for now, adds (x,z) to a seed location where x and z are both in the range of [-3,3]
- At the end of the generation of seed locations, we have a list of (x,z) pairs to place our seeds. We then plant these, and calculate how many were placed in the (-4,4) farmland section
Evaluation of the current agent
Below we evaluate our current agent compared to a random agent
Evaluation Method: Our aim in this section of the project was to beat a random agent with our genetic algorithm. So to test whether we were successful, we:
- First ran our random agent for 10 seperate rounds to get a baseline score
- We then ran our genetic algorithm for 10 seperate rounds to see how the scores compares
The scores are summarised in the chart below:
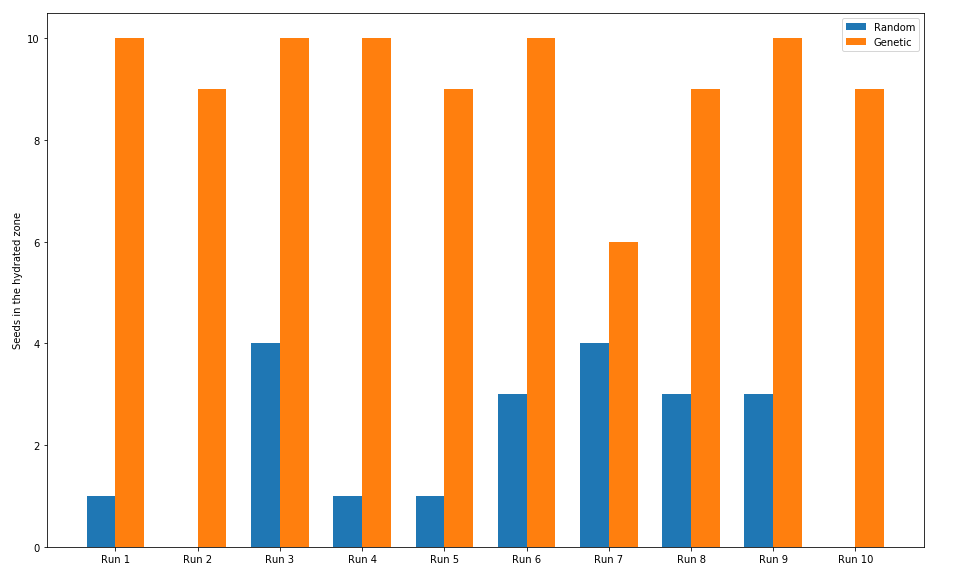
The blue bars in the chart above represent the random agent. As you can see, every trial of the baseline algorithm, underperformed compared to our genetic algorithm. Interestingly, if we calculate the average of the scores of the random agent, we get exactly 2 / 10, or 20%, which is very close to the estimated 18% earlier. If we did more trials, we would find that eventually the success rate of the random agent would tend to 18%.
Our genetic algorithm was very successful in this case, mostly planting 10 seeds in the optimal zone. The average overall came to roughly 9.2/10.
A further piece of information we gathered was how the global scores vary with the round. This gives us an overall picture of the convergence of the algorithm
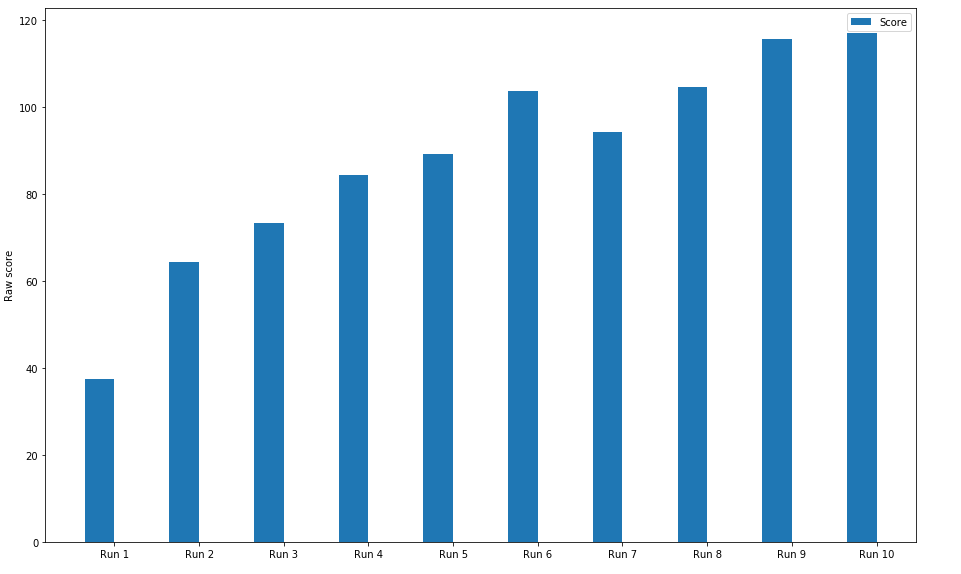
We see that, as we map the scores per round onto the chart, in the general case it will steadily rise and then finally by round 9/ round 10, we get very little difference
It is also interesting to see how to seeds converge on the water block. Below is a charting of different stages of the algorithm and how it progresses
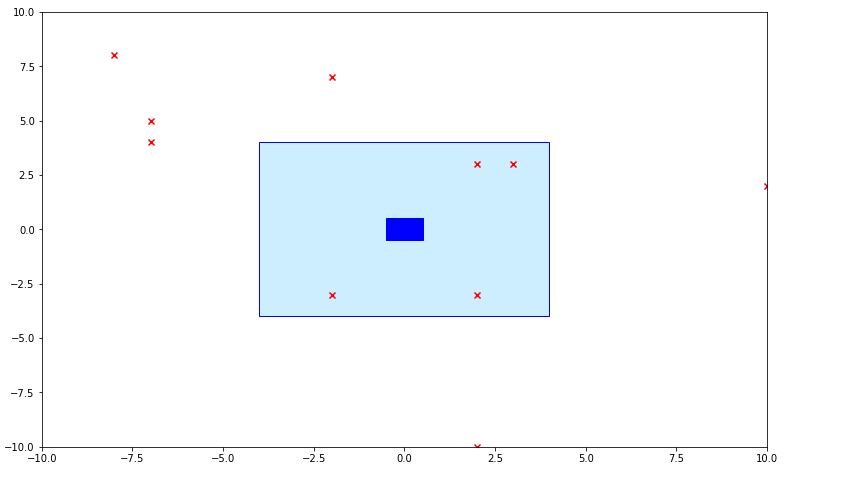
Round 1
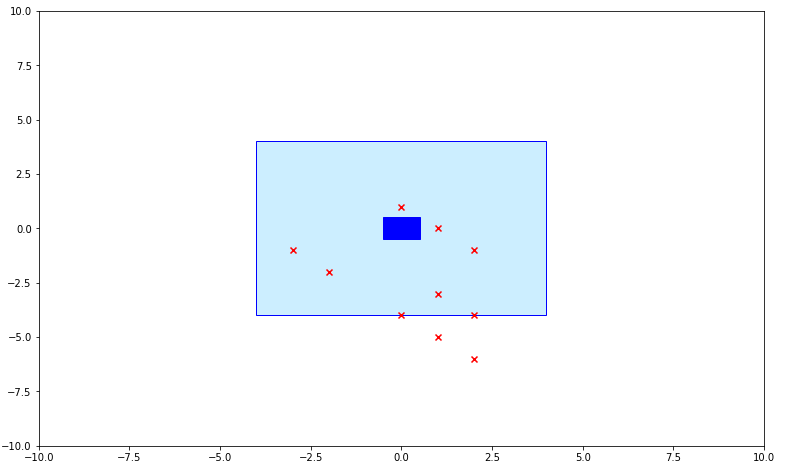
Round 3
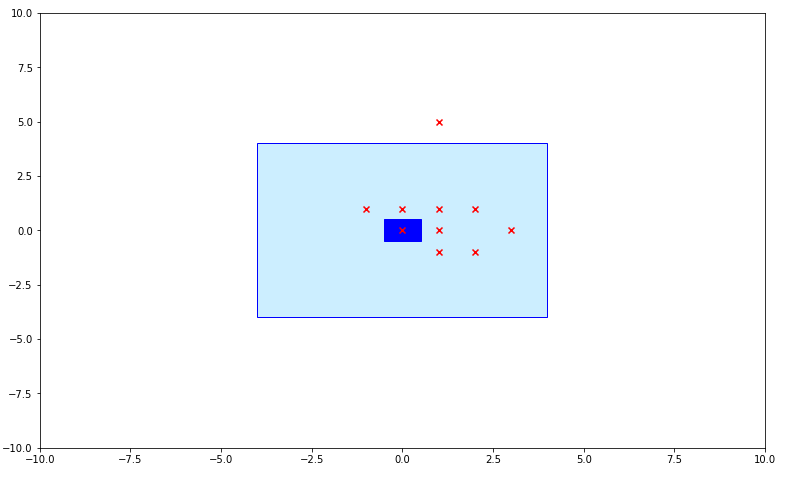
Round 6
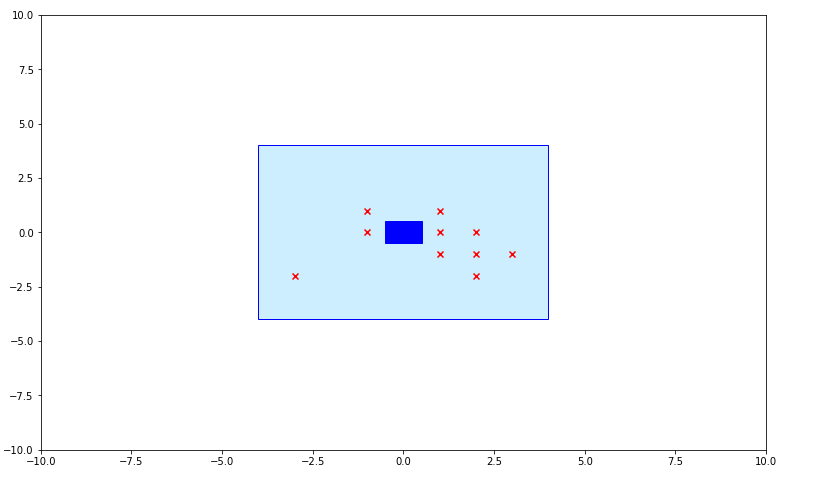
Round 8
By round 8 of 10 the seeds have converged
Remaining Goals and Challenges
At the moment we have a very basic algorithm that will give us a better score than randomly placing seeds, but we have identified three main points of improvment
-
Making the planting real
At the moment, our algorithm can be run fully out of malmo: we give it an array of where the locations of each block type are, and a scoring function, and the algorithm will give the best locations to place seeds after running some number of rounds consecutively.
So essentially this relies entirely on our score function: if the scoring function models the map sufficiently well, the plants will grow optimally. However, this does not scale/ would be quite complex to build. For now, we can only model distances from interesting squares, for example, the score we are currently using is distance from the nearest water block. But minecraft farming depends on much more than this: a torch in the neighbouring square to a crop will make it grow faster, which our score function will not pick up, and so if on a map a seed is planted nearby a torch, the model could assign it a bad score, despite it being a good square to plant on.
This is where the malmo APIs could become useful: after each round of the genetic algorithm, we could actually plant at the locations generated by the algorithm for that round, then reap the seeds some time later, and calculate our score for each of the seed locations based on how quickly/ how well the plant actually grew.
So our score function would become the reaction of the real minecraft environment, meaning that we get a more accurate model of where is best to plant in our world. This also has the implication that the score function becomes generic AKA it does not have to be rewritten for every map, since the actual environment gives us feedback
ChallengesThe malmo API does present a number of challenges when considering our project scope/ farming in minecraft in general. These include:
- Farming itself in minecraft is binary: although there are several "levels" of growth which would be useful for scoring the rate of the growth at a particular square, either the crop has grown or it hasn't, as far as the game is concerned when reaping the crops, meaning that rate of growth is difficult/ impossible to obtain with just the in-game APIs, meaning we would need some kind of computer vision solution to find whether one plant has outgrown another (unless one of the plants has grown fully and one hasn't).
- One of the biggest problems is planting and reaping consistently: we have noticed that, using the current teleport function, planting a seed on a square and then trying to reap it later from that same square doesnt always work, because items are thrust into the air when reaped. To mitigate this, we could make the player move around the square the plant was reaped in, so that the agent is more likely to pick up the crop.
-
Map Exploration
Inherently, the seeds are generated from the best seeds of the current round: so they will converge on the point(s) found by the best seed(s) in the first few rounds.
But what happens if all of the seeds are generated in a very bad location?
Currently to prevent this from happending, some "variance" vector is added to a point at the end of each round, which we included as the "mutation" aspect of the genetic algorithm with the hope of exploring the map slightly. However this doesnt quite solve the problem of making sure the map is explored if all seeds are generated on one side of the map, which means that we could end up converging on a minumum point in our map.
To solve this we will implement a smarter mutation algorithm: one improvement we have been considering is crossing over (breeding) two points from our "elite" set that are a maximum distance away, then taking the x coordinate from one parent and the y coordinate from the other parent. This means that the seed ends up in a totally new place for at least some seed generations, especially at the starting rounds.
Another mutation improvment could be something similar to the above, but instead taking the midpoints between the two furthest points. The best strategy, for overall best coverage of the map, could be a combination of the two techniques.
-
Convergence
At the moment, the genetic algorithm runs for 10 rounds. This was chosen through trial and error: when testing, it was found that this is the rough figure that the seeds converge on for this map. However a more rigorous definition of a cut off point must be found so that the algorithm can scale over to other maps.
Defining when our algorithm converges comes down to determining how much difference there is between successive generations. If all of the seed locations plants of the next generation have only moved by one square, the chances are that the algorithm has now converged and there is no need to continue.
Related Resources on Genetic Algorithms
Below is a list of resources we found useful when researching Genetic Algorithms
Matlab Article
This resource demonstrates how a genetic algorithm is used to find minimum points on a graph
A nice breakdown is given of the seperate stages of the genetic algorithm and how you can actually code up a solution by yourself
Visit here to see the article
Video Demonstration
The below video shows a nice visual animation on how genetic algorithms repeatedly take the best performing samples from the "gene pool" to eventually converge on a population that each finds itself on some optimal point.
See the video on youtube here
Washington University
This gives a brief insight into how genetic algorithms came about and a general overview of implementation
See it here
Wiki page
Gives a few good examples of genetic algorithms
See it here